|
Regresjon |
Hans-Petter Ulven
Webstart av siste versjon av GeoGebra:
Alle vet at det er storken som kommer med babyer, men i og med at noen trekker denne påstanden i tvil er det på sin plass å dokumentere dette med vitenskapelige, ugjendrivelige bevis! Vi bruker statistisk lineær regresjon til dette.
Den hvite storken, Ciconia Cicionia, er en vanlig fugl i mange
land i Europa, så vi har gode tellinger på bestanden.
Fra Teaching Statistics, volume 22, number 2, Summer 2000, har
jeg sakset disse dataene:
| Land: | Storkepar: | Barnefødsler: (103/år) |
| Albania | 100 | 83 |
| Østerrike | 300 | 87 |
| Belgia | 1 | 118 |
| Bulgaria | 5000 | 117 |
| Danmark | 9 | 59 |
| Frankrike | 140 | 774 |
| Tyskland | 3300 | 901 |
| Hellas | 2500 | 106 |
| Nederland | 4 | 188 |
| Ungarn | 5000 | 124 |
| Italia | 5 | 551 |
| Polen | 30000 | 610 |
| Portugal | 1500 | 120 |
| Romania | 5000 | 367 |
| Spania | 8000 | 439 |
| Sveits | 150 | 82 |
| Tyrkia | 25000 | 1576 |
Start GeoGebra med knappen:
Vis regnearket i GeoGebra med: Vis, Regneark.
Kopier disse dataene med Rediger, Kopier (eller Ctrl-C):
Lim deretter inn i regnearket ved å klikke i cellen A1, høyreklikk og velge: Lim inn.
Merk deretter tallene i regnearket med musen, høyreklikk og velg: Lag liste med punkter.
Kjøre en lineær regresjon med: f(x)=RegPoly[L_1,1].
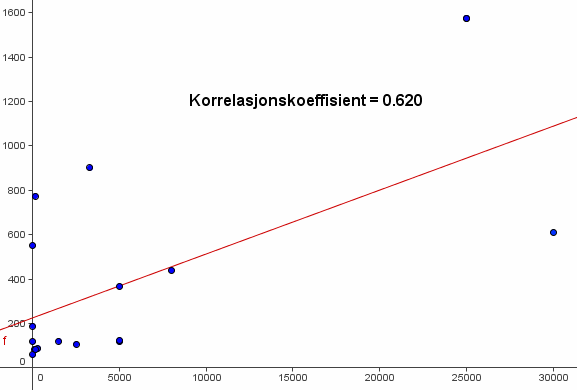
Vi ønsker også en korrelasjonskoeffisient, og regner derfor ut:
r=Korrelasjonskoeffisient[L_1]
I et tekstfelt kan vi vise resultatet ved å legge inn: "Korrelasjonskoeffisient = "+r
Da får vi noe slikt:
Ganske overbevisende, ikke sant?
(Det kan faktisk vises med en Students T-test at p-verdien her er 0.008, altså et meget signifikant resultat, selv om korrelasjonskoeffisienten kunne vært bedre.)
GeoGebra inneholder en rekke liste-kommandoer som kan regne ut diverse prametere:
Mean[<liste>], MeanX[<punkt-liste>], MeanY[<punkt-liste>], Median[<liste>], Mode[<liste>]
og alle summene som dukker opp i slike forbindelser:
SigmaXX, SigmaYY, SigmaXY, Sxx, Syy, Sxy,...
Summen av kvarderte avvik mellom modellen og dataene kan regnes ut som SSE=Sum[(f(x(L_1))-y(L_1))^2]
For andre kurvetilpasninger enn rette linjer er SSE en bedre vurderingsparameter enn korrelasjonskoeffisienten,
som egentlig sier noe om statistisk sammenheng mellom to variabler, ikke noe om kurven!
(Legg merke til at kommandoen Korrelasjonskoeffisient[<liste>] ikke bruker funksjonen for den rette linjen, bare dataene!)For et gitt datamaeriale kan korrelasjonskoeffisienten være 0.95, selvom en andregradskurve gir mindre SSE enn en rett linje!
Andregradskurven er da åpenbart en bedre modell og kurvetilpasning enn en rett linje!(Hvis leseren ikke tror dette, så er det en fin oppgave å legge ut noen punkter, få GeoGebra til å lage både en lineær og
kvadratisk kurvetilpasning, regne ut korrelasjonskoeffisienten og sse for begge kurvene, og deretter flytte punktene
til dere ser at dette er mulig.Så, selvom ordet "regresjon" brukes om kurvetilpasning, så er egentlig regresjon ordet for statistisk sammenheng
mellom to variabler, med korrelasjonskoeffisienten (kvadrert) som en statistisk parameter, mens kurvetilpasning
er å lage den kurven som passer best med datamaterialet i den forstand at sse er minst mulig.Så, selv om dataprogrammer og lommeregnere gir korrelasjonskoeffisient for annet enn rette linjer, så har denne
parameteren egentlig liten verdi og liten mening for ren kurvetilpasning.
Det er flere måter å sjekke om en lineær regresjon gir en modell som har noen statistisk verdi:
- Den enkleste sjekken vi kan gjøre er å fjerne noen av de åpenbart ekstreme punktene i tall-materialet,
og se om dette har stor innvirkning på regresjonsmodellen.
(Hvis de har det, er modellen tvilsom!)- Se om feilene, det vil si: errori=|yi-f(xi)| er omtrent normalfordelt, slik forutsetningene for modellen er.
Dette kan sjekkes ved å plotte errori som et passende histogram og se om det har lange haler eller er usymmetrisk, eksempelvis:
error=abs(f(x(L_1))-y(L_1)) gir liste
Histogram[<liste med klassegrenser>,error] gir et histogram- Vi kan også sjekke errori (med fortegn) mot yi, disse punktene bør ligge i et jevnt belte om x-aksen.
Hvis punktene ligger på en kurve, eller har trompet-form, er det grunn til å være skeptisk.
Gjør dette.- Egentlig sier kvadratet av korrelasjonskoeffisienten mer enn korrelasjonskoeffisienten;
tolkningen av r2 er at dette er andelen av avvikene som kan forklares med den lineære modellen vi har laget.Her har vi et datamateriale fra 2001 som viser sammenhengen mellom tilgjengelighet av skytevåpen og mord utført med skytevåpen for 18 land:
(Venstre kolonne er prosenten av private hjem som har skytevåpen, og kolonnen til høyre er antall drap med skytevåen per. 100000 innbyggere per. år.)
Vurder om disse tallene indikerer noen sammenheng. Er det noen svakheter her?